问题背景
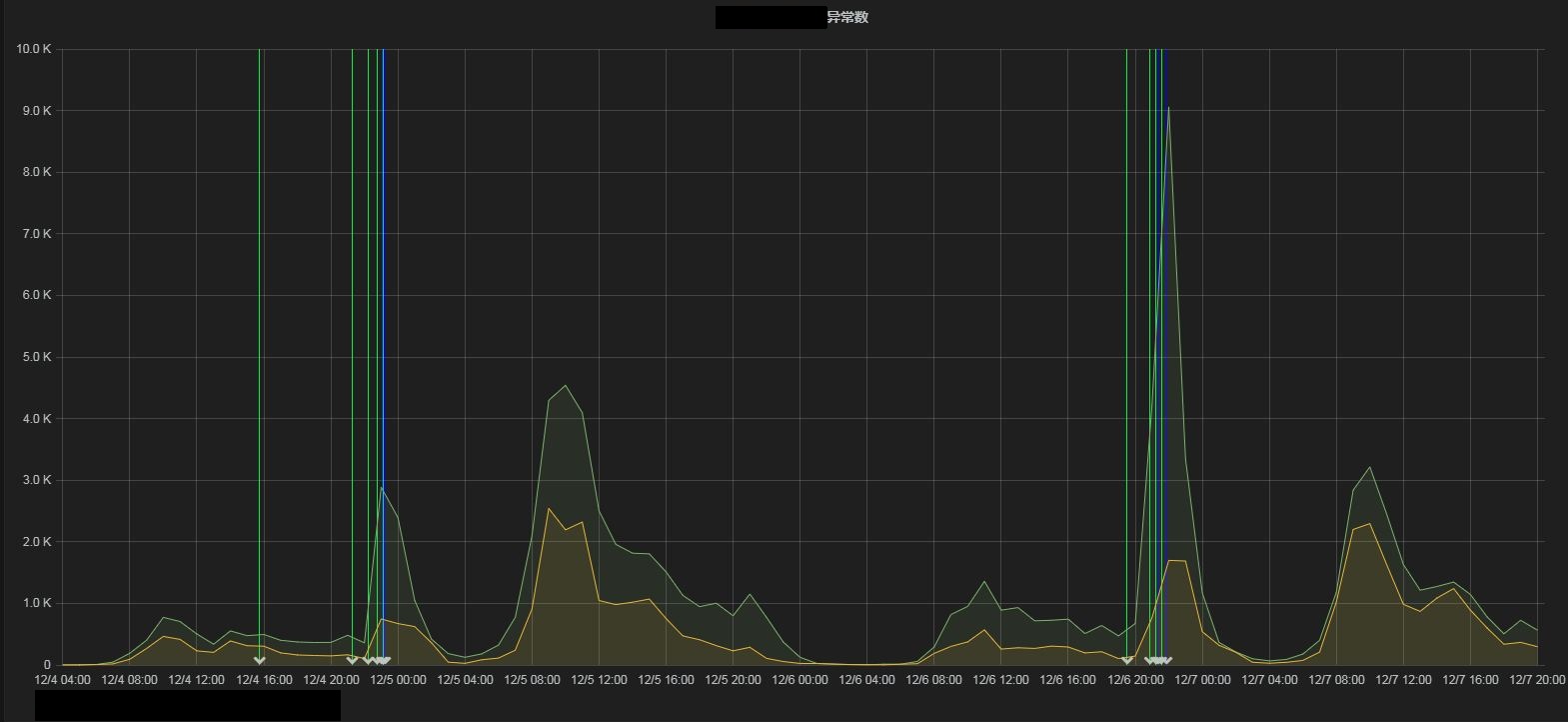
公司.net查询应用中有一个自实现的类似于 Guava Cache 的本地缓存管理组件,日常缓存项在10万到15万个之间。在一次改造后,添加了LRU缓存驱逐功能,实现的原理为经典的基于双链表的实现,即会维护一个包含所有缓存项的双链表,并按最近访问的先后顺序排序。问题在于功能上线后发现长耗时查询变多,对比原来翻了几倍,导致调用方超时报错变多。(绿线为发布时间点, 由图纵坐标可见超时异常最高达到9000)
排查过程
同事经过排查发现这些长耗时查询发生的时间点附近正好有Full GC发生,因此可以推断出这些长耗时查询是由于FuLL GC 的中断(stw)导致的。并且通过灰度下线一些机器的LRU缓存驱逐功能,比对有缓存驱逐功能和没有缓存驱逐功能的机器的差异,发现有缓存驱逐功能的机器Full GC 中断时长明显比没缓存驱逐功能的机器长。可以初步得出结论,新上线的LRU缓存驱逐功能导致Full GC 中断(stw)时间变长,从而导致长耗时查询的变多。
接下来的问题就是,为什么这个功能会导致Full GC 中断(stw)时间变长。首先怀疑的就是缓存驱逐功能引入的双链表数据结构对GC造成压力。 了解GC算法的应该都知道,目前.net的CLR和java的jvm,GC时都是通过可达性分析来查找存活对象,因此对象之间引用的复杂程度一定程度上会影响GC算法标记存活对象的时间。
按理来说一个链表也不是啥复杂的数据结构,为什么会对GC造成压力,对于这点我研究了一下,也找了不少资料,最终在《The Garbage Collection Cookbook》 (垃圾回收算法手册)这本书里找到答案:
某些垃圾回收问题的出现可能不利于使用并行回收。例如当标记-清扫回收器在对链表进行追踪时,链表固有的顺序特征决定了再追踪阶段的每一步中,标记栈中的仅会包含一个元素,即链表中下一个将被追踪的节点。在这一场景下,只有一个回收线程处于工作状态,其他线程均处于等待。在包含p个处理器的系统中,由于缺少工作而处于等待状态的标记线程数量n与任意可达对象的最大深度之间的关系为:n <= (p-1) * max depth(o) ,max depth(o) 为对象引用的最大深度
总结一下就是链表数据结构对于并行标记十分不友好,一个链表标记的过程中只有一个线程能够对其进行标记,而其他线程只能等待。而目前java的jvm或者是.net的CLR都具有并行GC的功能,并且在服务器模式下一般都会开启以减少GC的耗时。这就一定程度能解释为什么引入一个链表会对GC造成压力。
解决问题
确定问题原因后,现在需要解决问题。通过调研,我决定使用链表的游标实现替换原来的链表。链表的游标实现简单来说就是节点通过数组进行保存,每个节点保存下一个和上一个节点在数组中的索引进行链接。类似如下代码
public class ArrayLinkedList {
Node[] nodes;
private static class Node {
public T value
public int next;
public int prev;
}
}
一些语言诸如BASIC和FORTRAN不支持指针,如果需要使用链表,就需要使用游标(cursor)实现法来实现链表。
这样一来,对于应用程序而言,游标实现的链表仍然具有链表的性质,对于GC回收器而言,游标实现的链表就是一个数组,不仅利于GC的并行处理,而且对于CPU高速缓存更加友好。这也算一种迎合GC的编程方式吧。
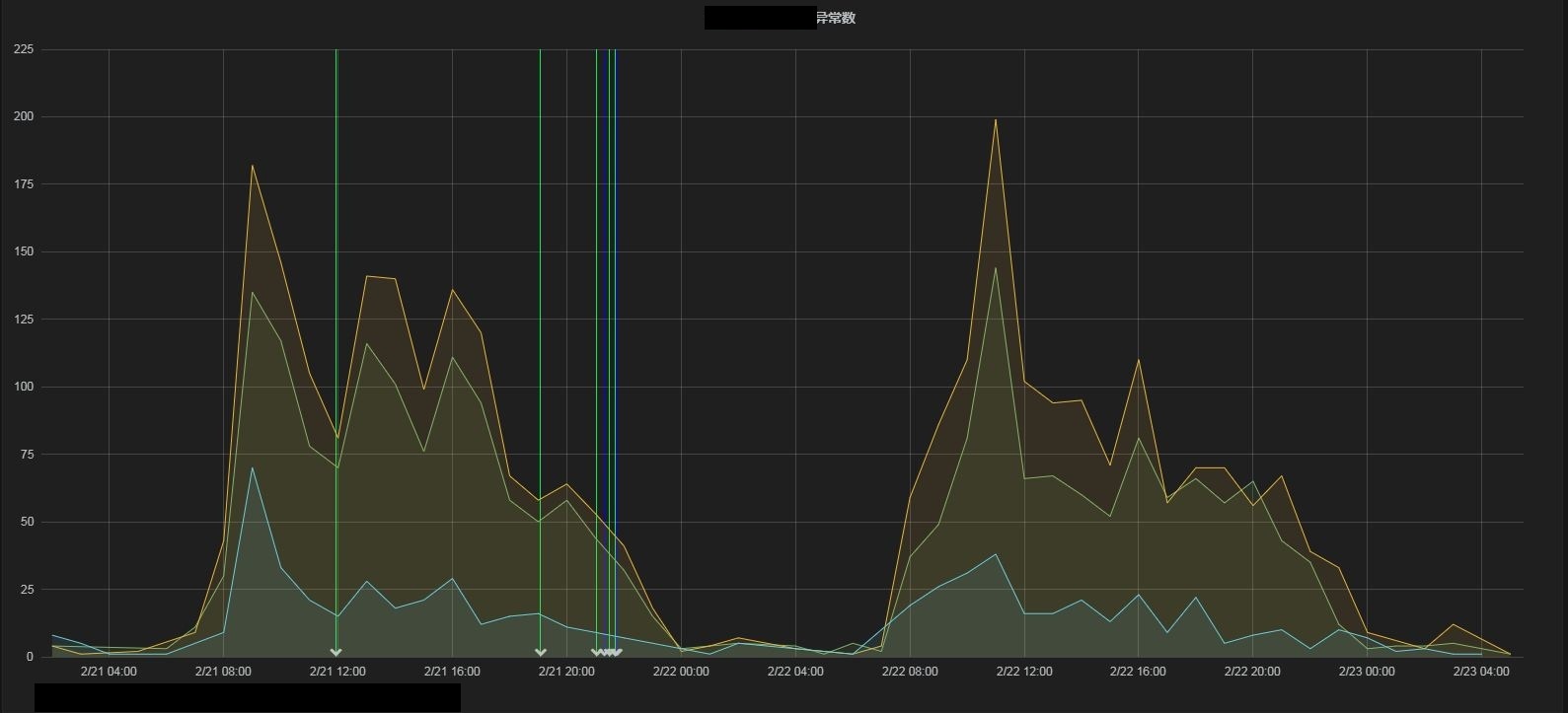
最终使用该方案改造重新上线后,由图纵坐标可见,超时异常最多仅到200,说明改造是有效果的。